仅需两步即可完成:
1. 打开 12306 项目 开源仓库主页,右上角点个 Star
2. 点击下方【同意授权检测】按钮,同意获取 API 权限进行检测
本章节文档,将在 Star 12306 仓库后正常开放展示
 揭秘车票查询背后的复杂性
揭秘车票查询背后的复杂性🚀 如何把12306项目“吃透”?
如果你正在为校招面试做准备,面临着简历上“烂大街”的项目,面试机会较少,或者希望将 12306 项目充实到简历中等问题,欢迎了解「拿个offer-开源&项目实战」知识星球。我们提供以下主要服务:
在文章正式开始前,大家打开 12306.cn 搜索一趟列车,根据搜索条件判断,数据搜索技术使用 ElasticSearch 或者其它搜索技术是否合适?
这里我先把答案说下,12306 车票搜索用的是 Redis ,而不是大家常用的 ElasticSearch。至于为什么?大家可以先思考下再继续阅读。
先来一张 12306 列车检索的截图,让大家看下 12306 都有哪些搜索条件。
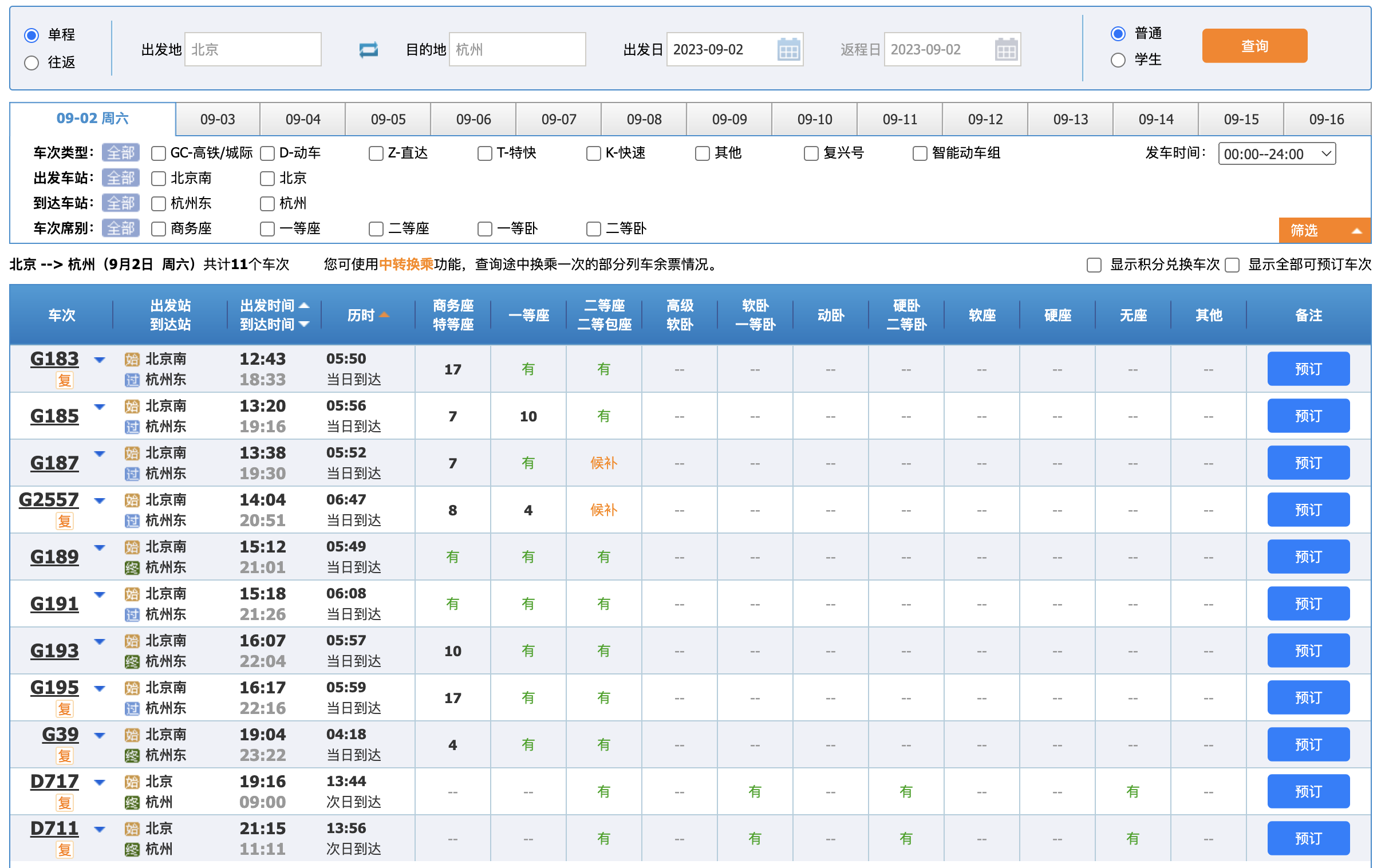
搜索条件如下:
许多同学都感到疑惑,因为搜索条件实在太多了,这似乎会严重影响数据库的性能。有些人甚至认为,如果性能不佳,至少应该使用 Elasticsearch 等搜索引擎来处理。这也是我一开始的想法,与大多数同学一致。
然而,随着进一步的思考,我发现了一个有意思的页面交互,这改变了我的看法。跟着马哥的思路,一起来深入探讨一下。
ElasticSearch 是一款非常强大的、基于 Lucene 的开源搜索及分析引擎;它是一个实时的分布式搜索分析引擎,它能让你以前所未有的速度和规模,去探索你的数据。
许多年前,一个刚结婚的名叫 Shay Banon 的失业开发者,跟着他的妻子去了伦敦,他的妻子在那里学习厨师。 在寻找一个赚钱的工作的时候,为了给他的妻子做一个食谱搜索引擎,他开始使用 Lucene 的一个早期版本。
直接使用 Lucene 是很难的,因此 Shay 开始做一个抽象层,Java 开发者使用它可以很简单的给他们的程序添加搜索功能。 他发布了他的第一个开源项目 Compass。
后来 Shay 获得了一份工作,主要是高性能,分布式环境下的内存数据网格。这个对于高性能,实时,分布式搜索引擎的需求尤为突出, 他决定重写 Compass,把它变为一个独立的服务并取名 Elasticsearch。
第一个公开版本在2010年2月发布,从此以后,Elasticsearch 已经成为了 Github 上最活跃的项目之一,他拥有超过 300 名 contributors。 一家公司已经开始围绕 Elasticsearch 提供商业服务,并开发新的特性,但是,Elasticsearch 将永远开源并对所有人可用。
据说,Shay 的妻子还在等着她的食谱搜索引擎…

Elasticsearch 提供了一个强大而灵活的搜索和分析引擎,适用于各种应用场景,包括日志分析、电子商务搜索、实时监控等。它具有高性能、可扩展性和可用性,能够处理大规模数据,并提供丰富的搜索、分析和可视化功能,帮助用户从数据中获取有价值的信息。
根据大家对 Elasticsearch 的了解,以及对 12306 复杂搜索条件的背景,肯定是 Elasticsearch 更适合实现改数据检索的功能。不急,咱们继续往下看。
Redis(Remote Dictionary Server)是一个开源的内存数据结构存储系统,被广泛应用于缓存、消息队列、实时数据分析、排行榜等场景。它提供了以下主要功能:

大家对 Redis 熟知的一些概念就是 Redis 非常快,那快是如何体现以及原理是什么?
考虑使用 Redis 和 Elasticsearch 两个技术都是有一定道理的,它们分别有自己的优势和适用场景。
作为承受请求最多的列车搜索功能,需要同时兼容实时性、并发性以及部署成本几大要点。为此,我梳理了为什么必须用 Redis 的几个原因。
公司实际用过 ElasticSearch 集群的同学应该知道,这玩意就是个性能深渊,非常消耗资源,懂得都懂。
到这里,许多人可能会有疑问,面对如此多的搜索条件,难道不应该使用 Elasticsearch 吗?然而,这正是要强调为什么选择 Redis 的关键原因。
您是否注意到了这张图的一个关键点?它只允许选择一天的出发日期。深思熟虑一下。
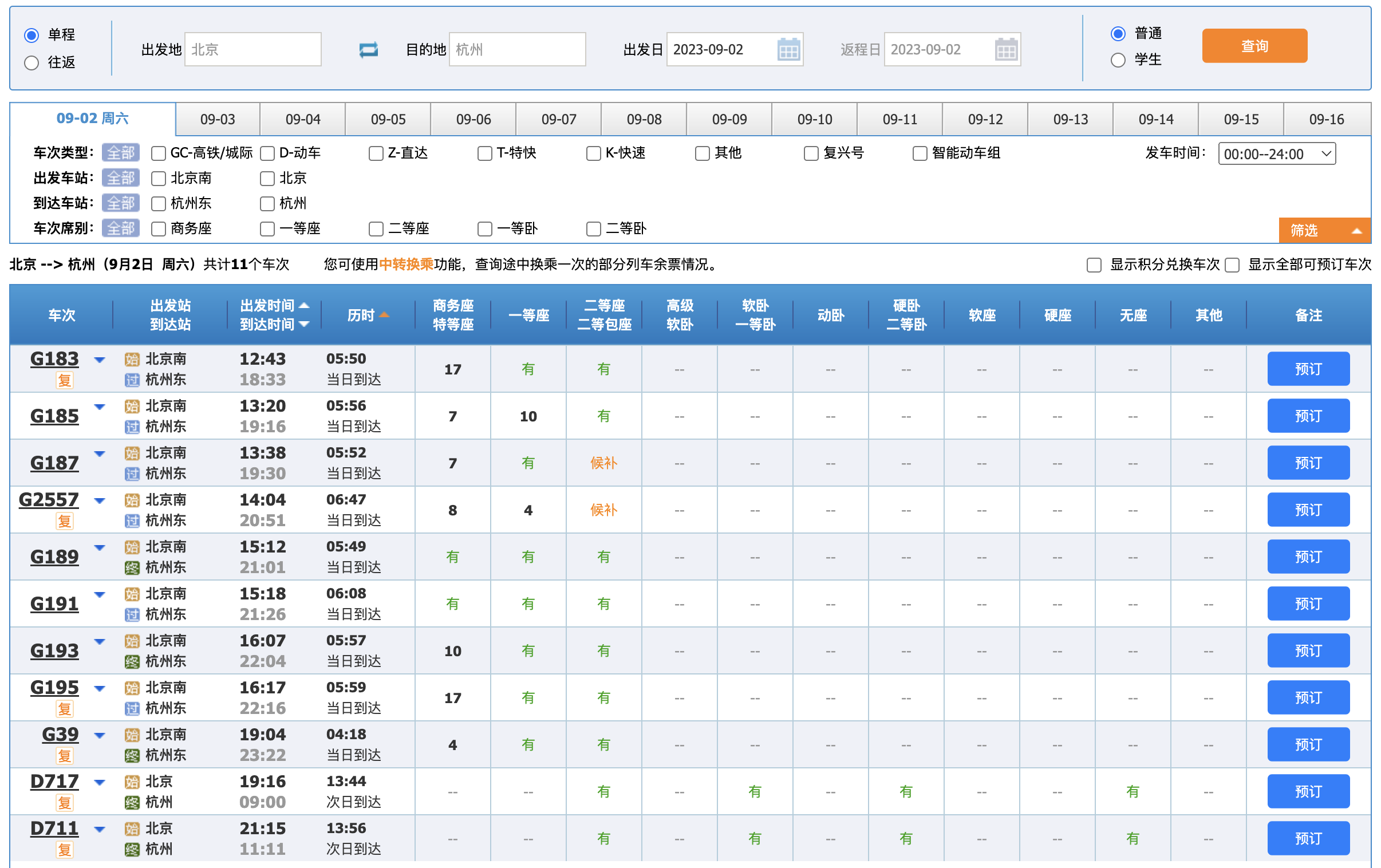
如果只能选择一天,那我们是不是可以这么来设计 Redis 缓存存储 12306 列车查询数据。

也许有些人会问,这么多的查询条件怎么处理呢?你可以亲自在12306网站上尝试,虽然页面上有很多查询条件,但大多数条件都是由前端进行筛选,实际上并没有触发后端的请求。
如果你不相信的话,可以观看下面的视频,你会发现只有在点击“查询”按钮时才会真正触发后端的请求,而点击页面上的其他筛选条件并不会向后端发出请求。
此处为语雀视频卡片,点击链接查看:12306列车查询请求示意.mov (opens new window)
12306 列车数据搜索具有多个搜索条件,包括单程/往返、出发地、目的地、出发日期/返程日期、乘客类型、车次类型、出发车站、到达车站、车次席别、发车时间、显示积分兑换车次以及显示全部可预订车次等。这些条件使搜索功能变得复杂,但在实际使用中,大部分条件是前端筛选,而不是每个条件都会发起后端请求。
在这种情况下,Redis 作为列车数据的缓存存储是有道理的,原因如下:
总的来说,Redis 作为列车数据的缓存存储在实时性、并发性和部署成本方面具有一些优势,尤其适用于快速检索和缓存常用路线数据。然而,对于复杂的全文搜索和高级查询需求,可以考虑将 Redis 与 Elasticsearch 等搜索引擎结合使用,以充分发挥它们各自的优势。