原因:开源不易,文档仅对已 Star 刚果商城项目的用户开放。
操作步骤:点击下方「Gitee 项目」和「GitHub 项目」按钮 Star 项目即可。 刚果商城所有端的代码都会完全开源,为了更好地完善这个框架,希望大家多多支持。
 时间分片按照消息ID查询
时间分片按照消息ID查询消息服务中有一张发送记录表,存储了所有消息类型的发送记录。随着时间的推移和业务的迭代,单表数据量将变得越来越大。
当 MySQL 单表数据量越大越大时,会出现以下几个危害:
因此,为了避免以上的危害,我们需要对大表进行拆分,采用分库分表的方式,把数据划分到多个库表中,使得单表数据量变小,从而提高数据库的查询效率、索引效率,减小攻击面,方便数据备份和恢复,提高系统的稳定性和安全性。
目前刚果商城中,消息服务 congomall-message 中消息发送记录表使用时间进行分表操作,一年分为 12 张表,一个月数据在一张表中。
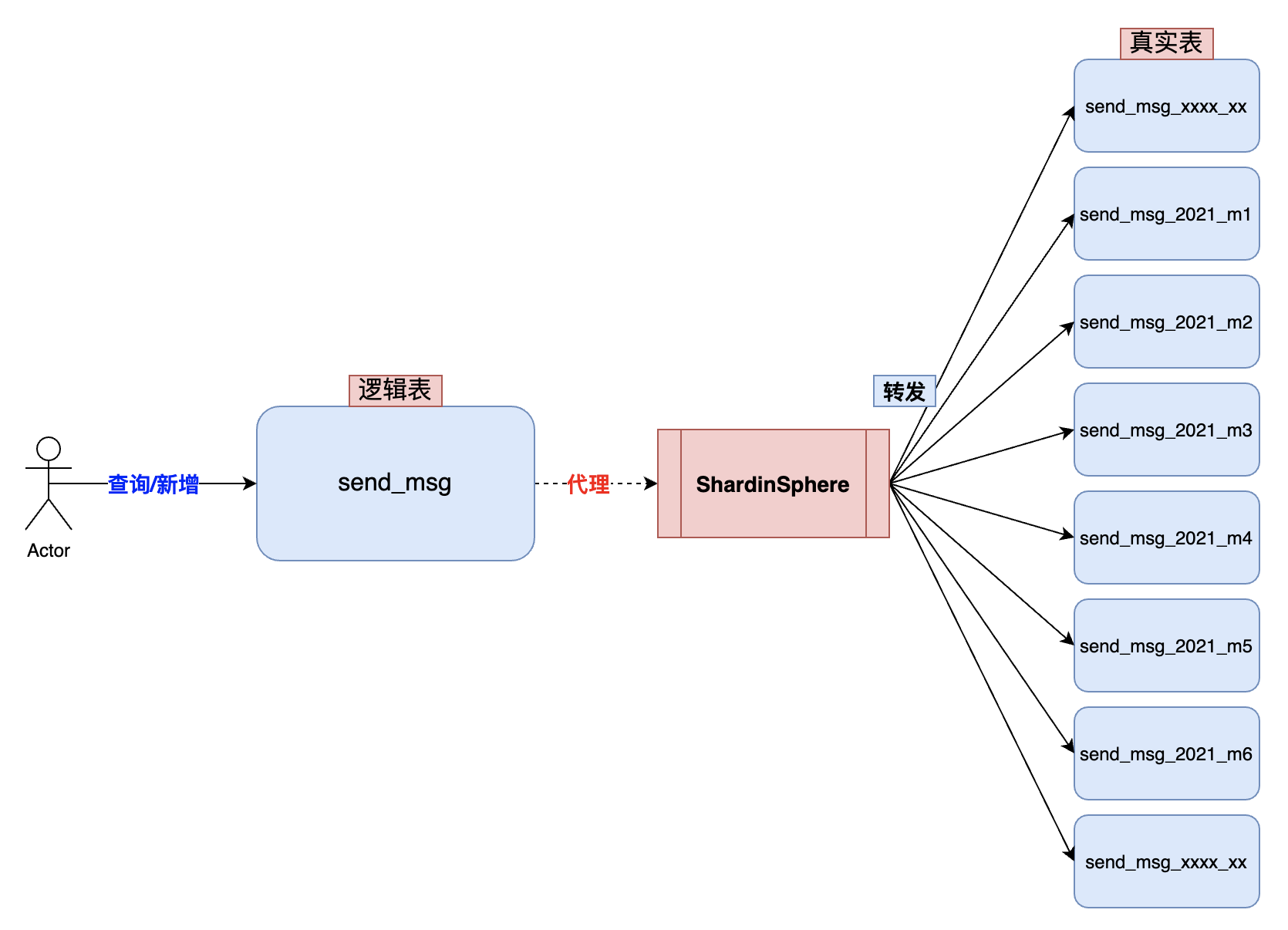
如果我开始不了解业务,看到这里的话,会有一点疑问:为什么不使用 Hash 分库分表?
在实际应用中,消息发送记录表不适合采用 Hash 分库分表,主要原因如下:
因此,对于消息发送记录表这种按照时间字段频繁查询的场景,采用按照时间字段分库分表更为合适。
通过按照时间字段进行范围查询,可以保证数据均匀分布在多个分片中,同时也可以避免 Hash 分表可能导致的数据分布不均的问题。此外,按照时间字段进行分片还能够提高查询性能,使查询更加高效。
消息发送表照时间分库分表,每个库中的表都是按照时间字段分成多个表,后续所有查询中条件必须带上时间字段,否则会走所有真实表扫描。
如果你想查询 2023 年 1 月份的消息发送记录,那么你的条件查询参数就要带上这个日期,语句如下:
SELECT * from send_msg WHERE create_time BETWEEN '2023-01-01 00:00:00' and '2023-01-31 23:59:59'
经过 ShardingSphere 对语句进行分片重组,将逻辑表改写成具体的物理表,语句如下:
SELECT * from send_msg_2023_m1 WHERE create_time BETWEEN '2023-01-01 00:00:00' and '2023-01-31 23:59:59'
上面说的是正常的场景,但是会存在一种很真实的问题,那就是在消息发送表未进行分表前,曾经提供出去过按照消息 ID 查询的条件。
咱们模拟下如果查询分片表不带分片键会发生什么事情?
用户期望的执行语句是:
SELECT * from send_msg WHERE msg_id = 'xxx'
但是实际执行会变成查询所有物理分表:
SELECT * from send_msg_2022_m1 WHERE msg_id = 'xxx' UNION ALL
SELECT * from send_msg_2022_m2 WHERE msg_id = 'xxx' UNION ALL
SELECT * from send_msg_2022_m3 WHERE msg_id = 'xxx' UNION ALL
SELECT * from send_msg_2022_m4 WHERE msg_id = 'xxx' UNION ALL
SELECT * from send_msg_xxxx_mx WHERE msg_id = 'xxx'
这种执行是一种性能深渊,基本上结果查询出来,接口也超时了。如果遇到大批量调用,极有可能把数据库查崩了。
那如何解决这种问题呢?
将消息 ID 根据时间戳映射到对应的时间表中进行查询,按照月分表,消息 ID 为 t,则可以通过 t%12 得到对应的表名,然后在该表中进行查询。
CREATE TABLE `send_msg_relation` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`send_msg_id` bigint(20) DEFAULT NULL COMMENT '消息ID',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
这样的查询效率比较高,但是需要维护消息 ID 和时间表的映射关系,同时需要处理跨表查询的问题。
而且,时间映射表还存在两个比较明显的缺点:
有没有一种既能高效查询,又不需要创建映射表的解决方案?
Snowflake 中文的意思是雪花,所以常被称为雪花算法,是 Twitter 开源的分布式 ID 生成算法。
Twitter 雪花算法生成后是一个 64bit 的 long 型的数值,组成部分引入了时间戳,基本保持了自增。

从雪花算法组成部分可以看出,其中包含完整的时间戳。因此,我们可以通过反解析消息 ID 来获取时间戳,并以此作为查询条件来查询对应的创建时间。
大胆设想,细心求证,接下来我们进行反解析试试。
核心原理就是通过位移将对应位数拿到,并取出我们想要的参数。
@Override
public SnowflakeIdInfo parseSnowflakeId(long snowflakeId) {
SnowflakeIdInfo snowflakeIdInfo = SnowflakeIdInfo.builder()
.workerId((int) ((snowflakeId >> WORKER_ID_SHIFT) & ~(-1L << WORKER_ID_BITS)))
.dataCenterId((int) ((snowflakeId >> DATA_CENTER_ID_SHIFT) & ~(-1L << DATA_CENTER_ID_BITS)))
.timestamp((snowflakeId >> TIMESTAMP_LEFT_SHIFT) + DEFAULT_TWEPOCH)
.sequence((int) ((snowflakeId >> SEQUENCE_BIZ_BITS) & ~(-1L << SEQUENCE_ACTUAL_BITS)))
.gene((int) (snowflakeId & ~(-1L << SEQUENCE_BIZ_BITS)))
.build();
return snowflakeIdInfo;
}
代码位置:
org.opengoofy.congomall.springboot.starter.distributedid.core.serviceid.DefaultServiceIdGenerator#parseSnowflakeId可以尝试编写一个单元测试,以确保从消息 ID 中获取的时间戳参数是正确的,并且能够将其转换为对应的创建时间。这个测试可以包含以下步骤:
如果测试通过,就可以确保按照时间分库分表,并利用消息 ID 进行查询时,能够正确获取对应的创建时间,避免了查询扩散问题。
@Test
public void parseSnowflakeId() {
Snowflake snowflake = new Snowflake(0, 0);
SnowflakeIdUtil.initSnowflake(snowflake);
DefaultServiceIdGenerator defaultServiceIdGenerator = new DefaultServiceIdGenerator();
long nextId = defaultServiceIdGenerator.nextId();
SnowflakeIdInfo snowflakeIdInfo = defaultServiceIdGenerator.parseSnowflakeId(nextId);
System.out.println(snowflakeIdInfo);
}
/**
* SnowflakeIdInfo(timestamp=1288834974657, workerId=0, dataCenterId=0, sequence=0, gene=0)
*/
测试成功,成功获取了时间戳参数,接下来我们可以利用该时间戳参数获取具体的时间信息,并通过创建时间字段进行查询。
可以考虑以下步骤实现该逻辑:
msg_id 和 create_time 作为分片键。new Date(timestamp) 的方式。SELECT * FROM table WHERE create_time = '2022-01-01 00:00:00' 的方式。通过上述步骤,就可以实现按照消息 ID 查询分库分表后的目标表了。
ShardingSphere 分片算法包括单分片算法和复合分片算法,前者适用于单个字段分片,后者适用于多个字段分片。
对于需要使用 msg_id 和 create_time 作为分片键的情况,需要采用复合分片算法。
由于内置的分片算法无法满足特殊场景,因此需要自定义复合分片算法。
ShardingSphere 对 SQL 进行分片的执行流程可以简单概括为以下几个步骤:
需要注意的是,在分片路由的过程中,ShardingSphere 还会对 SQL 进行一些额外的处理,比如计算分片键的值、将分片键的值转化成数据节点的名称等。这些额外的处理都是为了准确地将 SQL 发送到目标数据节点,确保 SQL 能够被正确地执行。
package org.opengoofy.congomall.biz.message.infrastructure.algorithm;
import cn.hutool.core.collection.CollUtil;
import com.google.common.collect.Range;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingValue;
import org.opengoofy.congomall.springboot.starter.distributedid.SnowflakeIdUtil;
import java.util.Collection;
import java.util.Date;
import java.util.LinkedHashSet;
import java.util.List;
import java.util.Map;
import java.util.Properties;
/**
* 自定义分片算法
*/
public final class SnowflakeDateShardingAlgorithm implements ComplexKeysShardingAlgorithm<Date> {
@Override
public Collection<String> doSharding(Collection availableTargetNames, ComplexKeysShardingValue shardingValue) {
final String messageSendId = "msg_id";
final String sendTime = "create_time";
String logicTableName = shardingValue.getLogicTableName();
Map<String, Collection<Comparable<?>>> columnNameAndShardingValuesMap = shardingValue.getColumnNameAndShardingValuesMap();
Map<String, Range<Comparable<?>>> columnNameAndRangeValuesMap = shardingValue.getColumnNameAndRangeValuesMap();
Collection<String> result = new LinkedHashSet<>(availableTargetNames.size());
if (CollUtil.isNotEmpty(columnNameAndShardingValuesMap)) {
Collection<Comparable<?>> sendTimeCollection = columnNameAndShardingValuesMap.get(sendTime);
if (CollUtil.isNotEmpty(sendTimeCollection)) {
Comparable<?> comparable = sendTimeCollection.stream().findFirst().get();
String actualTable = ShardModel.quarterlyModel(logicTableName, (Date) comparable);
result.add(actualTable);
} else {
Collection<Comparable<?>> messageSendIdCollection = columnNameAndShardingValuesMap.get(messageSendId);
Comparable<?> comparable = messageSendIdCollection.stream().findFirst().get();
String actualTable = ShardModel.quarterlyModel(logicTableName, new Date(SnowflakeIdUtil.parseSnowflakeId(((Long) comparable)).getTimestamp()));
result.add(actualTable);
}
} else {
Range<Comparable<?>> sendTimeRange = columnNameAndRangeValuesMap.get(sendTime);
if (sendTimeRange != null) {
List<String> actualTables = ShardModel.calculateRange(logicTableName, (Date) sendTimeRange.lowerEndpoint(), (Date) sendTimeRange.upperEndpoint());
result.addAll(actualTables);
} else {
result.addAll(availableTargetNames);
}
}
return result;
}
@Override
public Properties getProps() {
return null;
}
@Override
public void init(Properties properties) {
}
@Override
public String getType() {
return "CLASS_BASED";
}
}
完成自定义分片算法后,需要将其与 ShardingSphere 进行集成,并在 ShardingSphere 的配置文件中设置相应的分片规则。
接下来,可以编写一个简单的测试程序,通过向分片表中插入数据和根据消息 ID 查询数据的方式,来验证分片算法的正确性和可用性。如果测试成功,就可以使用该分片算法来对大表进行分库分表,并实现更高效的数据查询和管理。
spring:
shardingsphere:
datasource:
ds-0:
driver-class-name: com.mysql.jdbc.Driver
type: com.zaxxer.hikari.HikariDataSource
names: ds-0
props:
sql-show: true
rules:
sharding:
sharding-algorithms:
snowflake_date_algorithm:
props:
algorithmClassName: org.opengoofy.congomall.biz.message.infrastructure.algorithm.SnowflakeDateShardingAlgorithm
strategy: complex
type: CLASS_BASED
tables:
send_record:
actual-data-nodes: ds-0.send_msg_$->{2023..2026}_m$->{1..12}
table-strategy:
complex:
sharding-algorithm-name: snowflake_date_algorithm
sharding-columns: create_time,msg_id
调用 Apifox 在线接口消息中心目录下-根据条件查询发送结果,在数据库中找到一条记录,假设你找的是 send_record_2023_m4,那么接口入参传递以下:
{
"startTime": "2023-04-01 00:00:00",
"endTime": "2023-04-30 00:00:00",
"receiverList": [
"这个替换成数据库记录 {receiver}"
]
}
ShardingSphere 生成的真实 SQL 如下:
SELECT id,msg_id AS messageSendId,template_id,msg_type,sender,receiver,cc,status,send_time,create_time,update_time,del_flag FROM send_record_2023_m4
WHERE del_flag=0
AND (create_time BETWEEN ? AND ? AND receiver IN (?)) ::: [2023-04-01 00:00:00.0, 2023-04-30 00:00:00.0, m7798432@163.com]
该 Case 成功通过测试,我们可以看到 ShardingSphere 分片规则已经将创建时间字段正确地路由到了对应的真实表中。
调用 Apifox 在线接口消息中心目录下-根据消息发送ID查询发送结果,在数据库中找到随意一个消息发送 ID,拼接到 result 路径后 http://localhost:8001/api/message/result/{messageSendId}。
ShardingSphere 生成的真实 SQL 如下:
Actual SQL: ds-0 ::: SELECT id,msg_id AS messageSendId,template_id,msg_type,sender,receiver,cc,status,send_time,create_time,update_time,del_flag FROM send_record_2023_m4
WHERE del_flag=0
AND (msg_id IN (?)) ::: [1643084443437445120]
使用消息 ID 1643084443437445120 进行时间戳解析,成功定位到数据库真实表 send_record_2023_m4 并完成期望的查询。
通过本文的介绍,我们了解了如何通过 ShardingSphere 对消息发送记录表按照时间进行分库分表操作,并通过解析消息 ID 雪花算法中时间戳组成部分,可以依据消息 ID 高效分片查询。具体流程如下:
综上所述,使用 ShardingSphere 对消息发送记录表进行分库分表操作,并结合消息 ID 解析雪花算法中的时间戳组成部分,可以实现高效的分片查询,从而提高数据库的性能和扩展性。